

2022-23 年,我還在香港當工程師。
那時候的我非常羨慕外國的工程師,偉大的防火牆讓我無法正常使用許多 AI 工具,AI 看起來就像是另一個世界的科技。
後來我發現 GitHub Copilot 在香港不用 VPN 也能跑,馬上刷了 $100 USD 訂閱體驗一下。
還記得第一次看到在 VSCode 裏打幾個字後出現一堆 Placeholder,按個 Tab 就自動補好幾句程式碼,那種感覺真的爽到不行!
當時我拿 Copilot 給同事看,他們已經覺得我走在最前線了。
直到我搬來加拿大,能直接使用 OpenAI API,才真正開始接觸 AI 各種 AI 工具。
而我第一個念頭是:
做一個能根據公司內部文件回答問題的 Chatbot

為什麼會想做 Internal Chatbot?
原因很簡單:公司文件亂成一團。
除了初創公司之外,在我以前待的中大型公司遇到問題時,常常要先從一堆內部資料找頭緒,例如內聯網、Confluence、JIRA、Google Doc、FTP 伺服器…
就算找到了,大部份也沒有統一的文件格式。
有人是圖像派、有人是純文字派,而更多人是相信程式碼能自己說話,乾脆不寫文件。
曾經有團隊試圖統一格式,做了個模版讓大家跟著寫,但無奈舊文件實在太多沒人想動,新文件又總是有「更急的事」而草草了事。
幾年後團隊一換人,那套格式自然也就失傳了。
所以我想做一個擁有公司內部知識的 Chatbot,幫工程師回答常見問題,或者至少從垃圾場中翻出一兩個可能有用的連結,總比花個幾小時還只能找到個桔要好。
第一步就走錯了路
當時的我對 RAG、Embedding、Retrieval 這些完全沒有概念,只是一股腦地想玩 Gen AI,找點新技術來嘗鮮。
在 OpenAI 文件看到 Fine-tuning 的介紹,說得好像能教模型客製化的知識,一時熱血上頭,就這樣衝進去了。
第一次嘗試,我是用 Excel 手動建立資料集,裏面有 Prompt 和 Completion 兩欄。
我自己寫了大約 240 行問答配對,然後丟去 Fine-tune。
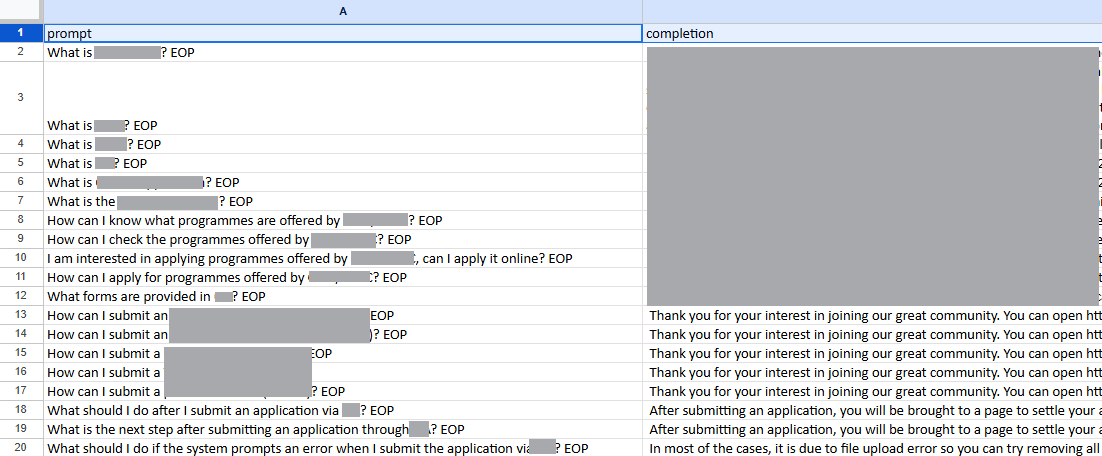
結果,模型答得一塌糊塗,還不時出現亂碼。
後來我改變策略,改為同一問題寫 5 種問法,讓資料量擴充到 1100 行後再來一次。
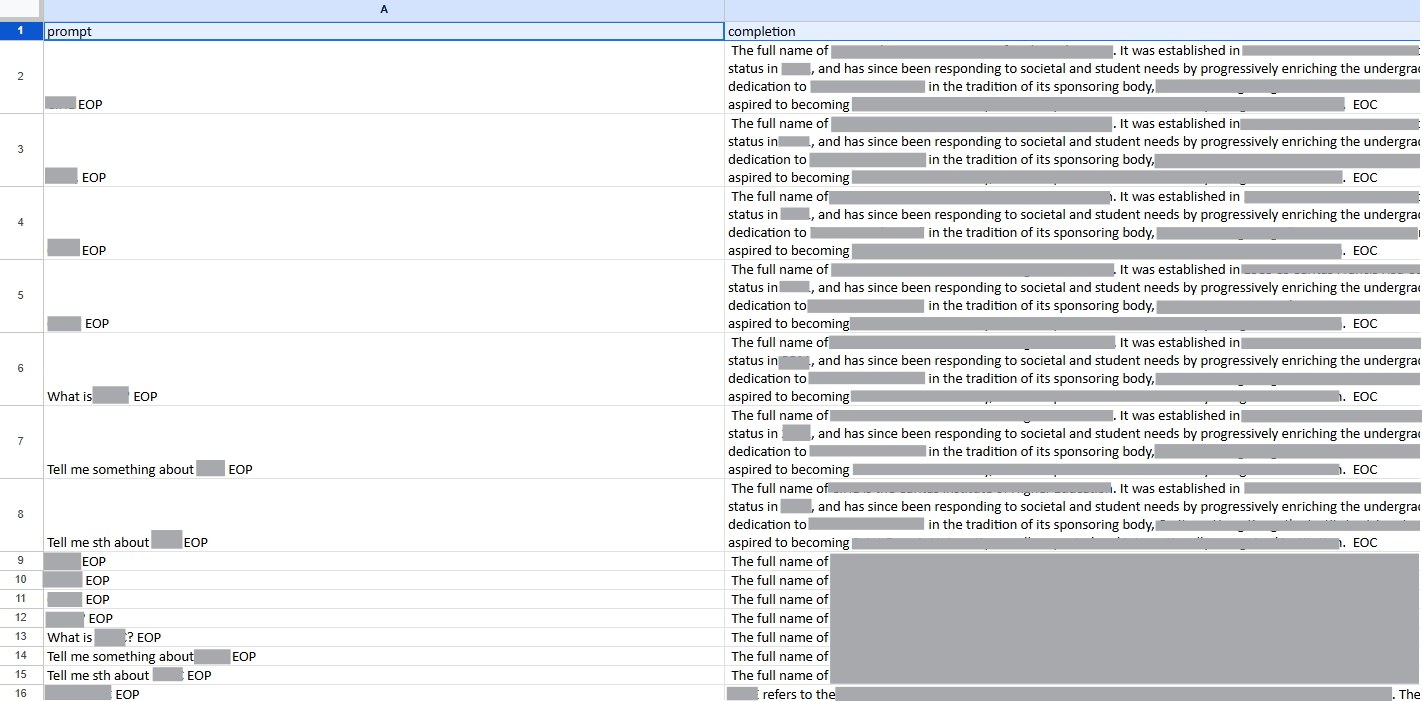
這次好一點,偶爾能答出我想要的內容,但大多時候還是答非所問,甚至會憑空捏造沒提供的資訊。
當時我也沒深究怎樣的資料才叫好,整理資料的方法只是自己摸出來的,歡迎各路大神指錯🙏🏻
盲目追新技術的教訓
多試幾次後,我意識到光靠自己是很難把模型 Finetune 得好的。
一來需要大量的資料,二來我缺乏相關知識。
最後我選擇暫停這個實驗,但這段經驗也讓我學到兩件事:
模型像小孩,而不是 API
它不像傳統 API 一樣能被準確控制,不是我寫一行就跑一行。
更像的是一個小孩,而工程師就像父母,要一直餵它資料,靠大量例子、適當的獎勵及懲罰去引導它學習。
這對習慣掌握流程的工程師來說是一種全新的開發體驗。
資料的質最為重要,但也不能忽視量
「Garbage In, Garbage Out」這句話,在 AI 開發裏是鐵則。
資料的品質不用多說,內容含糊不清或有誤導,模型學到的就是垃圾 (難怪需要 Data Engineer 這專業了😂)。
同一時間資料太少也不行,它就像人一樣,一知半解最危險。考試前只看講義,不做練習題,通常都考不出好成績。
想了解更多關於 Fine-tuning 的資料可以參考此網頁。
雖然這次只做到一個簡單的 POC 就停下來,但它讓我知道 Gen AI 開發也許沒有想像中那麼遙不可及 (雖然還是很難啦😂)。
也許正是這次經驗,種下了現在決心深入研究 Gen AI 的種子。
這是我電子報《打工仔也想學 AI》新系列的第一篇,下一篇將會寫:
同樣的問題,為什麼我後來選擇 RAG 而非 Finetune
怎樣在本地環境用低規格電腦跑 LLM
如果你對實作細節有興趣的話,歡迎繼續讀下去。
一些實作細節
以下是我 2 年前的一些筆記,現在可能已經不能用或有出錯,想要最新的資訊請參考此連結。
我當時用的是 OpenAI 平台來嘗試,所以想動手試的話記得先註冊一個 OpenAI Platform 用戶。
準備資料
在 Excel 第一欄的第一行寫上 “prompt”,第二欄第一行寫上 “completion”,然後在每一行第一欄填上問題,第二欄填上答案 (例子可參考第一步就走錯了路的附圖)。
根據 Microsoft 的文件,Finetune 用的資料最少要有 10 行,建議有幾百甚至上千行。
把 Excel 轉換為 JSONL 文件
安裝 OpenAI CLI
pip install openai用 OpenAI 內建的工具來轉換準備好的 Excel 文件為 JSONL 格式
openai tools fine_tunes.prepare_data -f <path to file>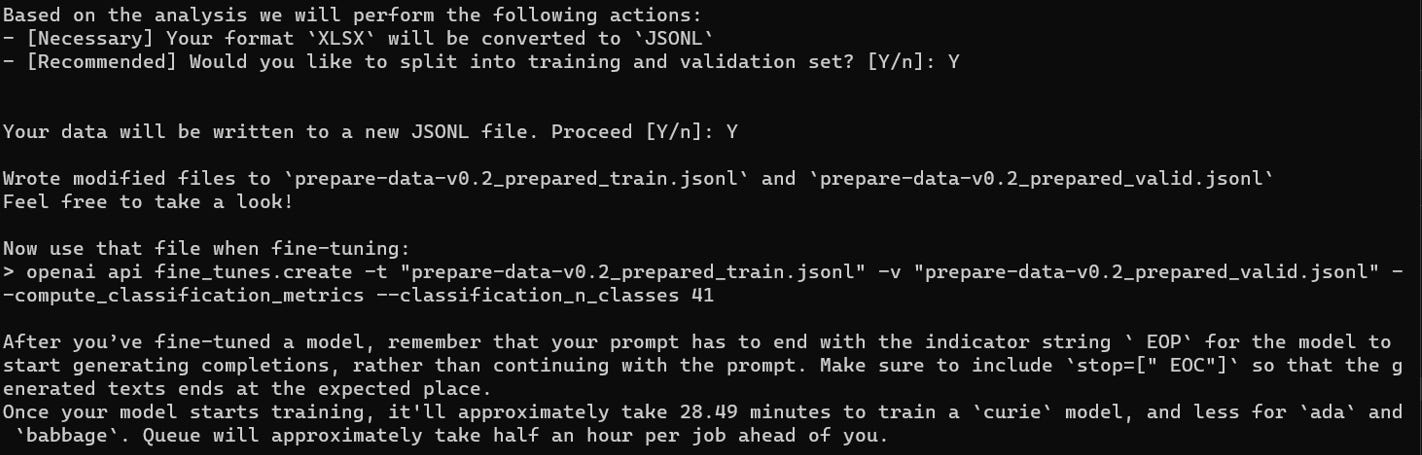
完成後會生成兩份 .jsonl 檔案,亦提供了下一步的指示
選擇基礎模型並開始 Finetune
在 OpenAI 模型列表中選擇一個基礎模型,我當時用的是 ada,現在好像已經沒這個模型了。
選好後就開始進行 Finetune,我選擇的是 Classification 工作,當時的我也不清楚這是什麼,只是試了幾次後感覺這模式結果比較好😂
openai api fine_tunes.create -t "<path to prepared_train.jsonl file>" -m <model name> -v "<path to prepared_valid.jsonl file>" --compute_classification_metrics --classification_n_classes 41提交工作後它會回傳一個 ID,可以用來查詢 Finetune 的進度。
openai api fine_tunes.follow -i <id>當 Finetune 完成後就可以到 OpenAI Playground 選擇該模型聊天了🎉
現在回 OpenAI 的網頁看,以上用 Cli Finetune 模型的方法好像已經不再支援了,取而代之是用平台上的 UI 或 API。
雖然這套流程現在已經不一定能用,但它記錄了我第一次動手訓練模型的過程,也讓我感受到原本自己也能參與這場 AI 革命。
技術一直會變,但學會主動探索、犯錯、從失敗中尋找下一步,才是工程師最重要的核心能力。
I have seen this description of LLMs a couple months ago, and I really like it: "leaky abstraction". And in my experience, the less intelligent the model, the more leaky it is.